以前球隊在回防時, 教練總會說"快跑! 別回頭, 到定點再休息".
關於人生, 喘息點在哪兒? 我想就在滴水穿石之間!
Deep Learning <–> keep learning
Week31 (08/04)
網路文章
A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN
- R-CNN: https://arxiv.org/abs/1311.2524
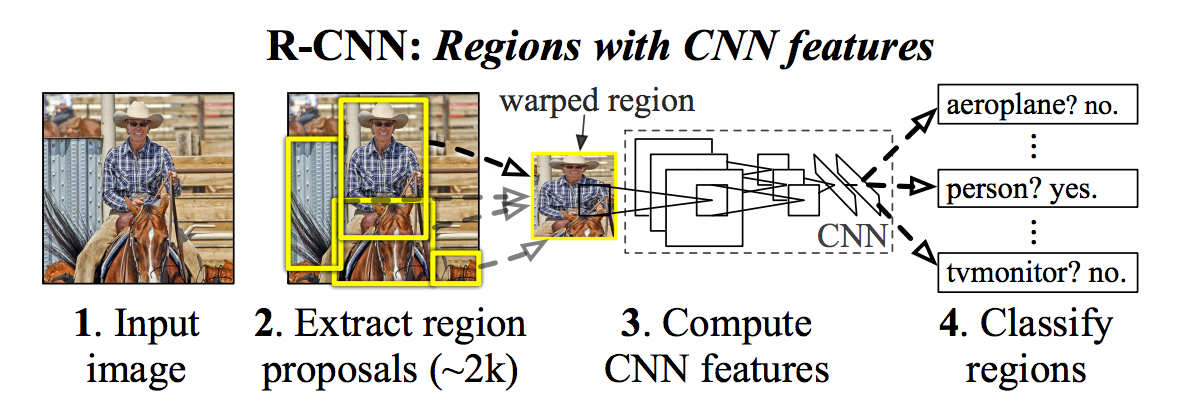
Visual Recognition就是從這裡爆發了… 透過Selective Search找到Region後丢給修改過的AlexNet學習, 最後再給Support Vector Machine (SVM) 這層CNN.
原本設計的R-CNN就只做這些:
- 用Selective Search找region
- 透過pre-trained AlexNet去算特徵後交給SVM看region裡的是什麼鬼東西
- 最後透過線性回歸(linear regression)畫出物件的座標
- Fast R-CNN: https://arxiv.org/abs/1504.08083
Region proposals using Selective Search.
- RoI (Region of Interest) Pooling
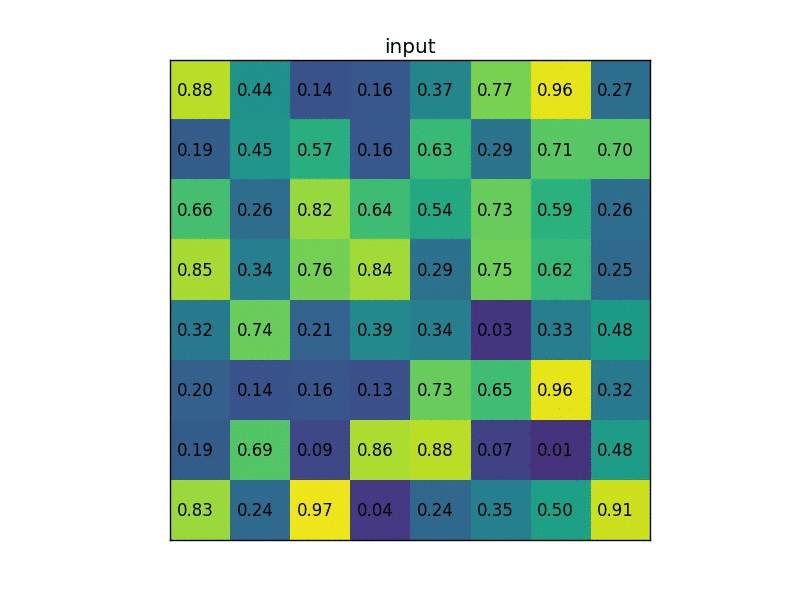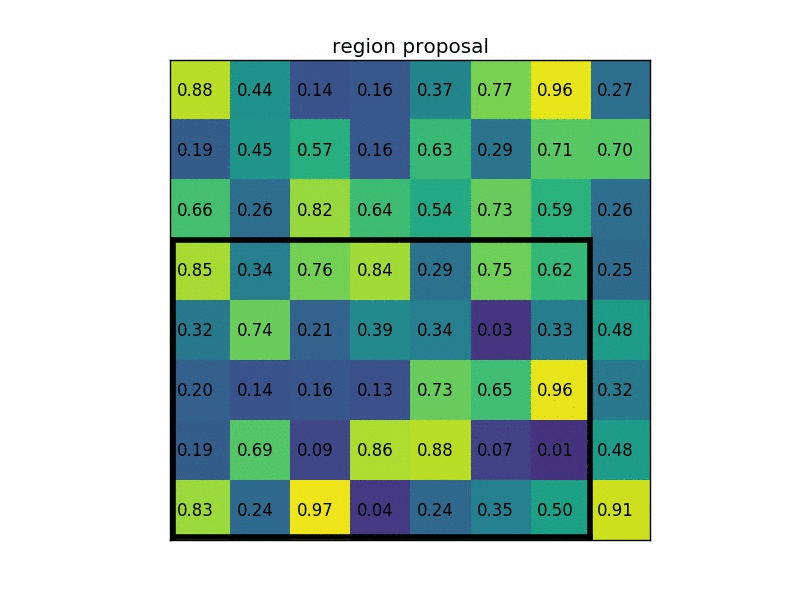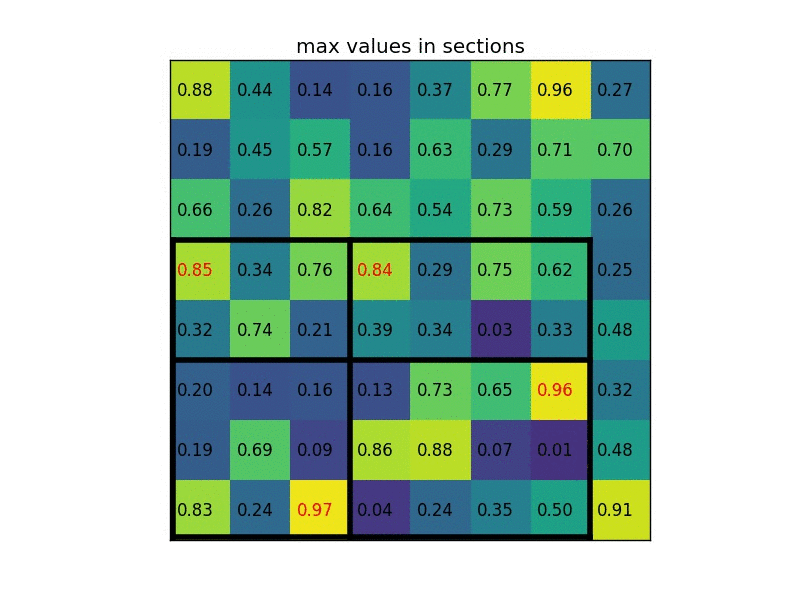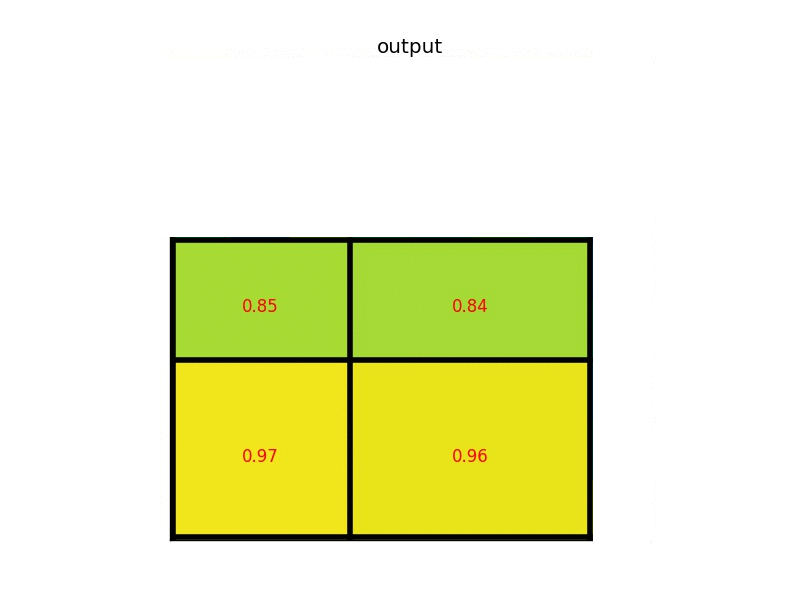
- Combine All Models into One Network
將R-CNN的AlexNet, SVM, Regressor整合在一起變成單一個network Fast R-CNN instead used a single network to compute the extract image features (CNN), classify (SVM), and tighten bounding boxes (regressor).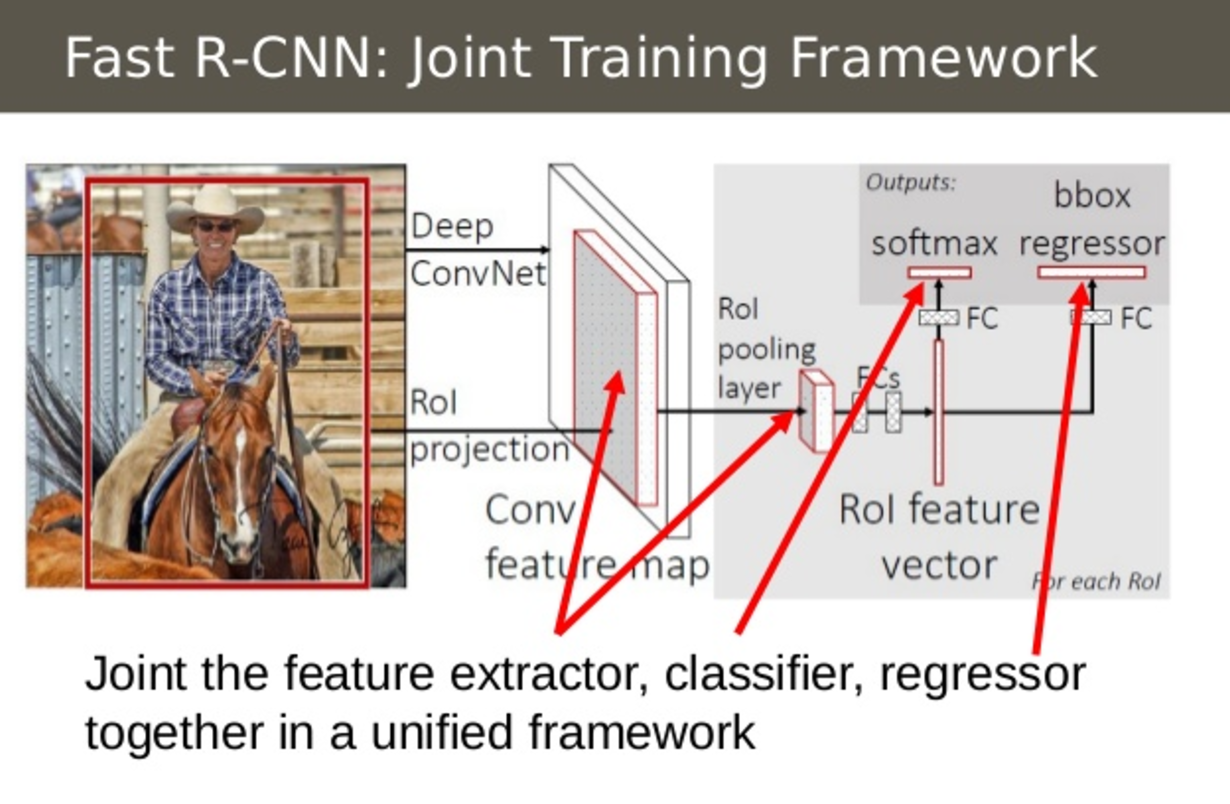
Faster R-CNN: https://arxiv.org/abs/1506.01497
用SS找region的方法太慢, 又重覆計算, 改由RPN後, 整個framework只要訓練一個CNN.
Speeding Up Region Proposal: Selective Search is too slow.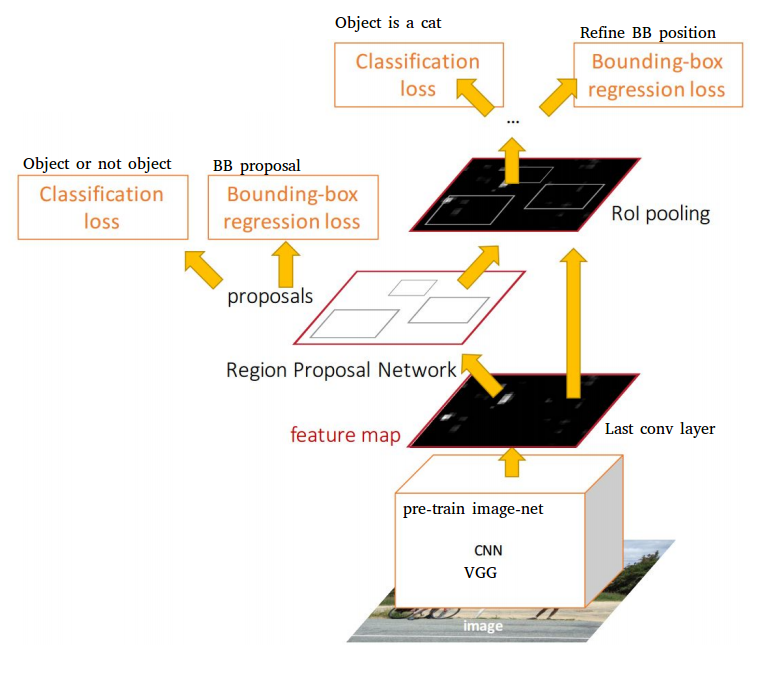
A single CNN is used to both carry out region proposals and classification.
only one CNN needs to be trained
Region Proposal Network(RPN) - How the Regions are Generated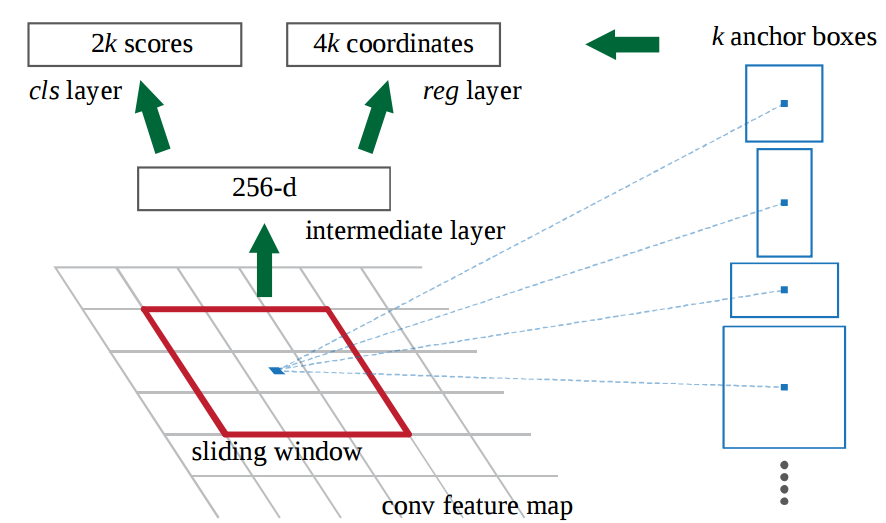
Mask R-CNN: https://arxiv.org/abs/1703.06870
Extending Faster R-CNN for Pixel Level Segmentation
Facebook的reseachers發現RoIPool在選擇region時會有誤差, 所以利用RoiAlign來處理這個問題.
RoiAlign - Realigning RoIPool to be More Accurate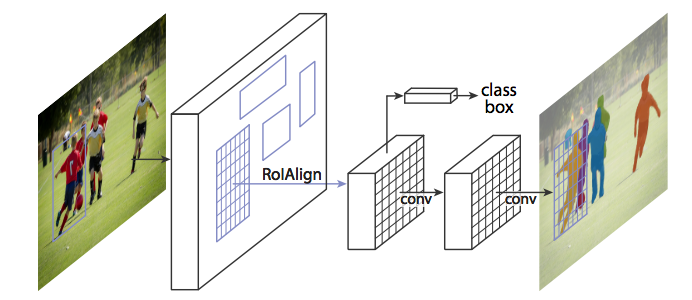
網路資源
CS231n Convolutional Neural Networks for Visual Recognition
Stanford的課程 - CS231n: CNNs for Visual Recognition.
6 Free to Low-Cost Resources to Teach You Calculus in a Fun and Interactive Way
對微積分有興趣可參考一下
讀書心得
Deep learning 近來的發展主要是在convolutional neural networks(CNN)
R-CNN(2014) -> Fast R-CNN(2015) -> Faster R-CNN(2016) -> Mask R-CNN(2017)
自2010年開始Image Net每年都有發表ILSVRC(Large Scale Visual Recognition Challenge)結果
在2015年時top-5 error rate為4.84%, 人眼辨識大約為5%, 造成了極大的影響.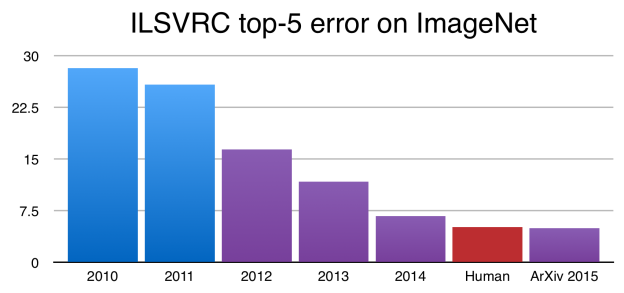
現在ILSVRC2017結果也公怖了, 基本上2015後top-5 error己經不是重點了吧.
Neural Network training 簡單的說就是算權重, 像在做filter (low/high pass filter)
每個hidden layer 處理的東西不同, ex: 點, 線, 面, 空間.
後來Google brain 的reseachers在2014提出了GAN(Generative Adversarial Network), 基本架構是2個neural network相互較勁來學習.
GAN主要可用在:
- 造假圖, 也就是透過學習把原圖做成不同風格的圖片.
- 電腦對戰
- 動畫或gaming材質的處理, 用來生出不同材質的貼圖
Deap Learning發展方向:
- 看圖說故事
- 軌跡預測
目前CNN的應用上大多使用VGG-16 pre-trained model, 再自行做fully connecte的訓練, 只需要少量的圖檔(300 or 600張)即可達到需求.
簡單的說就是拿訓練好的network, 調整權重(weights), 再經過小量的訓練即可.
R-CNN 及 Fast R-CNN用selective search找region裡有沒有東西, 是比較沒有效率的方法, input是使用224x224大小的圖, 所以𠩤圖需要scale down特徴值可能會失真.
後來的Faster R-CNN可以看成是RPNs(Region Proposal Networks) + Fast R-CNN, 可以避免特徴值失真, 不用縮圖.
Region Proposal Network
Faster R-CNN Training
Artificial Inteligence - Object Localization and Detection
PS:
Top-5 error rate: 對一個label猜5次, 猜中的機率.
Nvidia GTX 1080 Ti GPU使用Faster R-CNN, 1秒大約可以處理3張圖.
Week32 (08/11)
Week33 (08/18)
網路文章
Meet the Company That’s Using Face Recognition to Reshape China’s Tech Scene 大陸政府的加持對於新科技發展速度真是一大助力.
Week34 (08/25)
網路文章
Introduction to Trainspotting
Raspberry Pi + TensorFlow 偵測火車行進方向
網路資源
Mathcha
較直覺的方式寫數學公式, 比起MathJax方便.